white box testing
White box testing is a software testing methodology that uses a program's source code to design tests and test cases for quality assurance (QA). The code structure is known and understood by the tester in white box testing, in contrast to black box testing, a methodology in which code structure is not known by the tester and Gray box testing, an approach to QA testing in which some code structure is known to the tester and some is not.
White box testing takes an inward look at the internal framework and components of a software application to test the internal structure and design of the software. White box testing is also called transparent, clear and glass box testing for this reason. This testing type can be applied in unit, system and integration testing.
White box testing usually involves tracing possible execution paths through the code and working out what input values would force the execution of those paths. The tester, who is usually the developer that wrote the code, will verify the code according to its design- which is why familiarity with the code is important for the one initiating the test.
White box testing, on its own, cannot identify problems caused by mismatches between the actual requirements or specification and the code as implemented, but it can help identify some types of design weaknesses in the code. Examples include control flow problems (e.g. closed or infinite loops or unreachable code) and data flow problems. Static code analysis (by a tool) may also find these sorts of problems but does not help the tester/developer understand the code to the same degree that personally designing white-box test cases does. Tools to help in white box testing include Veracode's white box testing tools,
Advantages & disadvantages
Advantages to white box testing include:
- Thorough testing.
- Supports automated testing.
- Tests and test scripts can be re-used.
- Testing is supported at earlier development stages.
- Optimizes code by removing any unnecessary code.
- Aids in finding errors or weaknesses in the code.
Disadvantages include:
- Test cases are often unrepresentative of how the component will be used.
- White box testing is often time consuming, complex and expensive.
- Testers with internal knowledge of the software are needed.
- If the software is implemented on frequently, then time and cost required
White box testing vs black box testing
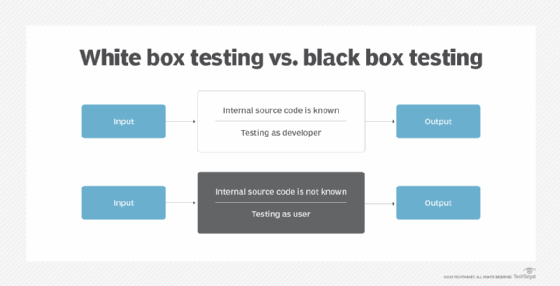
Black box testing is the opposing form of testing compared to white box testing. The implication is that you cannot see the inner workings of a black-painted box; and in fact, you do not need to. Black box testing will design test cases to cover all requirements specified for the component, then use a code coverage monitor to record how much of the code is executed when the test cases are run. Unlike white box testing, black box tests do not need developers who worked on the code. All the testers need to be familiar with are the software's functions. Other differences between black and white box testing are that black box testing is based on requirement specifications rather than design and structure specifications. Black box testing can be applied to system and acceptance tests as well as unit and integration tests.
Gray box testing is often used for internal software structures that







