Why use POST vs. GET to keep applications secure
Although POST and GET HTTP requests essentially perform the same command on a Web server, a security expert says there are inherent dangers in using one over the other. Learn why one type of processing request provides more security for your Web application in this expert tip.

It's the age-old question: is the POST method better than the GET method for processing HTTP requests? The common response is always use POST. Problem solved. Security breaches in recent years involving mishandled and unsecured information between the browser and the server have helped to underscore this importance. But why? What difference does it make if you use POST versus GET requests in your applications? Here's just what you need to know.
At a high level, when interacting with a Web server POST requests place user parameters in the body of the HTTP request. On the other hand, GET requests place such parameters in the URL. Big deal, you say? The same data is being sent regardless. That's true, but the problem lies in how HTTP operates. With GET requests, there are numerous ways for sensitive information to be exposed as shown in the graphic below.
Looking at the realities of this vulnerability, once a user of your application submits sensitive information via GET requests, anything's fair game. User credentials, form data, you name it ends up in clear text in numerous locations mostly out the user's control and quite often out of your control as well. In today's world of compliance and litigation, this isn't how you want to treat sensitive information.
On the workstation side, browser history files containing sensitive GET requests are easily recovered, especially when an unauthorized user gains access to the system. Specific cases could include a lost or stolen laptop (which are very simple to gain access to if the hard drive is not encrypted), a shared computer, or a situation where someone has shared out their local C: drive on the network granting everyone access. Browser history files are also vulnerable during cross-site scripting attacks.
On the server side, you've got Web server logs which are often stored indefinitely and easily searchable when the local C: drive has been shared out (something see quite often in my internal security assessments). There's also the risk of sensitive information users submit to your applications ending up proxy logs which are sometimes run by a third party. Yet another variable in the breach equation.
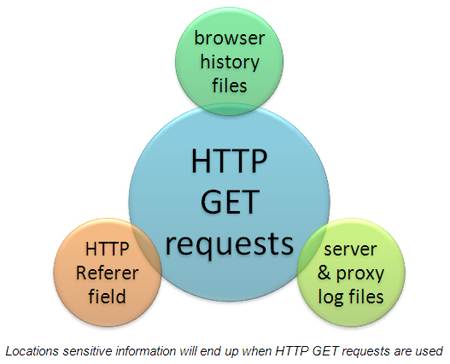
Finally, there's the HTTP Referrer field that can inadvertently expose sensitive user information. For instance, if the user is on your site and they click on or manually enter another URL any GET request information can be exposed to yet another party via the browser's HTTP referrer field. This doesn't mean the third-party site is malicious but it does mean that sensitive information has possibly been transmitted in an unsecure fashion and could stay on their servers indefinitely.
I'm not seeing GET requests being used all that often but when I do it's usually a big exposure. Sure, it could be argued that GET requests don't create a direct "exploit" but it's pretty much guaranteed that sensitive information is going to end being carelessly spread around the Internet nonetheless. Nothing may ever come of it but when and if it does it'll be clear how the problem came about. The POST method is certainly not the silver bullet given that sensitive data is still transmitted in the HTTP request and, thus, can still be captured and manipulated. However, security is about taking reasonable steps to eliminate the urgent and important stuff – especially the low hanging fruit – in order to minimize risk where you can. Do yourself and your business a favor and avoid using GET requests at all costs.
About the author: Kevin Beaver is an independent information security consultant, speaker and expert witness with Atlanta-based Principle Logic, LLC. He has over 20 years experience in the industry and specializes in performing independent information security assessments revolving around compliance and information risk management. Kevin has authored/co-authored seven books on information security including the ethical hacking books, Hacking for Dummies and Hacking Wireless Networks for Dummies (Wiley). He's also the creator of the Security On Wheels IT security audio books.







