Get to know the version control process
Distributed version control systems use is on the rise, particularly because they aid in collaborative development. Learn the basics of version control to get started.

Version control systems enable teams of programmers, as well as testers and other contributors, to track and make project changes from one software version to the next. The version control process details how software's source code changes over time.
With the proliferation of Git, Mercurial and other options, distributed Version control systems (DVCSes) surpassed the centralized approach, in which developers make changes to a single copy of code stored on a server. By contrast, with a distributed system, developers can use these version control concepts to make changes to their individual copies of a software repository and combine these changes in the master.
Programmers should know the core version control process, commands and entities to develop in teams without setbacks or conflicts.
Version control fundamentals
Source code: This is the suite of language-specific instructions that forms the basis of any software application. With version control systems, application development teams control and track changes made to software's code. Throughout the version control process, programmers move, copy or change the source code or code base.
Repository: This term refers to a storage location that contains the entire body of source code and versions of the software. In a DVCS, individual team members perform and save their work as an individual copy of the project's repository.
However, when a programmer is ready to share her completed work with the team, she will upload her changes to a remote repository. Typically, programmers only push (upload) changes to remote repositories or pull (download and incorporate) other team members' contributions to their own repository.
Commit: A programmer performs a commit during the version control process when he wishes to save a new version of the code base to a repository. For example, in Git-based systems, a programmer runs the git commit command. This action adds a new iteration in sequence after its parent commit -- the version from which the programmer worked. For each commit, a programmer typically writes a note that details changes or additions.
Products and vendors
Many programmers use Git or commercial products based on Git as a version control system. Many vendors support Git with their version control products, such as Microsoft's GitHub and Azure DevOps Server, GitLab and Atlassian's Bitbucket. Mercurial, which Bitbucket also supports, is a distributed alternative to Git.
There are also centralized version control options, such as Azure Repos, formerly called Team Foundation Version Control. Other products, such as Helix Core, enable customers to opt for either a distributed or centralized version control system.
Tracked and untracked files: Files that exist in a version control index are tracked files. Untracked files either exist outside of a version control system or are explicitly ignored by it.
Version control process and actions
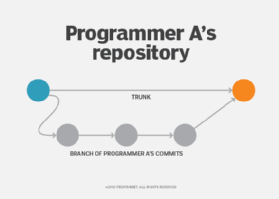
Trunks and branches: The version control system represents the various software versions as nodes laid out in treelike sequences, with each commit linked to its respective parent commit. Development can diverge to create different features or experiment with isolated changes to the source code in branches.
Each separate branch operates as an extension of the trunk, also called the master branch. On such pathways, developers can create parallel versions of the software and eventually merge them back into the trunk. Users eventually merge changes and additions made in commits on other branches into the latest commit on the master, which creates a new version of the software source code. When this happens, the latest commit in that branch and the master branch become parent commits.
Checkout: Before a programmer starts to work on a new branch, he must indicate to the version control system that he will work on that branch through a checkout. Checkouts ensure there is a record of who works on what, and they prevent conflicts that occur when multiple devs work on the same thing at the same time.
Take the example of a Git-based system. A programmer will run the git checkout command to begin work on a new branch. The command moves a pointer within the version control tool, a HEAD, that denotes which branch a programmer is working on.
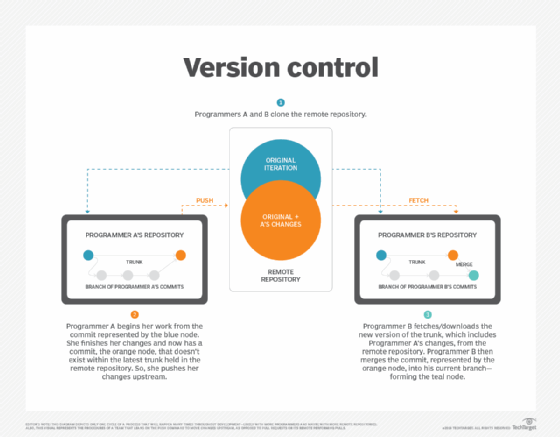
Clone: Programmers don't borrow code from any central repository in a version control system. Instead, they clone (copy) the entire remote repository onto their local machines.
Fork: Similar to cloning, a fork occurs when a programmer copies the source code. With a fork, however, the programmer spins off the copied source code to create an entirely new piece of software; she does not intend to contribute any commits or code to the original project. She uses the older project's source code as a starting point but takes the software in a different direction than the parent software intends.
Merge: The merge process integrates a programmer's changes from one branch into the trunk or another branch. A team's workflow determines which branch changes merge -- and where. The team also determines whether the changes are just a completed feature -- then likely just a development branch in a remote repository -- or a version meant for release. In the latter case, the team would likely merge both a remote repository's development branch and master.
Sometimes, a programmer might merge a branch back into the master before he completes a feature or some specific code changes, such as when the trunk has progressed far from when that branch was created. He can then create a branch again to resume work on the feature or code changes, with the assurance that the code base he works from is more in sync with the master branch in the team's remote repository.
Fetch: Programmers perform the fetch command to download information from other repositories to their local copy. A fetch, however, does not merge this information with your branch; it merely updates the local repository.
Pull: This command goes several steps beyond a fetch. Consider how git pull runs both git fetch and git merge. A pull acquires changes from a remote repository and then merges them into the branch a programmer is currently working on.
For example, if the remote version of the trunk diverged from the code in a developer's local repository, a programmer can initiate a pull to fetch the desired commit from the remote repository and merge it with a selected commit in the local master branch. This process creates a new commit, with both the commit in the remote repository and local master branch now denoted as parent commits.
On the same note, a programmer can send a pull request to other team members when she has changes she wants them to incorporate into their local clones. A pull request simply causes the targeted repository to take the latest code from a selected local repository.
Push: This process occurs when a programmer uploads his contributions from the local repository to a remote repository. In other words, this action asks the targeted repository to pull changes from the local repository of the programmer who initiates the push, as soon as possible.




