performance testing

What is performance testing?
Performance testing is a testing measure that evaluates the speed, responsiveness and stability of a computer, network, software program or device under a workload. Organizations will run performance tests to identify performance-related bottlenecks.
The goal of performance testing is to identify and nullify the performance bottlenecks in software applications, helping to ensure software quality. Without some form of performance testing in place, system performance may be affected by slow response times and inconsistent experiences between users and the operating system (OS).
In turn, this creates an overall poor user experience (UX). Performance testing helps determine if a developed system meets speed, responsiveness and stability requirements while under workloads to help ensure more positive UX.
Performance tests should be conducted once functional testing is completed.
Performance tests may be written by developers and can also be a part of code review processes. Performance test case scenarios can be transported between environments -- for example, between development teams testing in a live environment or environments that operations teams monitor. Performance testing can involve quantitative tests done in a lab or in production environments.
In performance tests, requirements should be identified and tested. Typical parameters include processing speed, data transfer rates, network bandwidth and throughput, workload efficiency and reliability.
As an example, an organization can measure the response time of a program when a user requests an action; the same can be done at scale. If the response times are slow, then this means developers should test to find the location of the bottleneck.
Why use performance testing?
There are a number of reasons an organization may want to use performance testing, including the following:
- As a diagnostic aid to allocate computing or communications bottlenecks within a system. Bottlenecks are a single point or component within a system's overall function that holds back overall performance. For example, even the fastest computer functions poorly on the web if the bandwidth is less than 1 megabit per second. Slow data transfer rates might be inherent in hardware but could also result from software-related problems, such as too many applications running at the same time or a corrupted file in a web browser.
- For software testing to help identify the nature or location of a software-related performance problem by highlighting where an application might fail or lag. Organizations can also use this form of testing to ensure they are prepared for a predictable major event.
- For testing vendor claims to verify that a system meets the specifications claimed by its manufacturer or vendor. The process can compare two or more devices or programs.
- For providing information to stakeholders to inform project stakeholders about application performance updates surrounding speed, stability and scalability.
- For avoiding gaining a bad reputation, as an application released without performance testing might lead it to run poorly, which can lead to negative word of mouth.
- For comparing two or more systems to enable an organization to compare software speed, responsiveness and stability.
Performance testing metrics
A number of performance metrics, or key performance indicators (KPIs), can help an organization evaluate current performance.
Performance metrics commonly include the following:
- Throughput. How many units of data a system processes over a specified time.
- Memory. The working storage space available to a processor or workload.
- Response time, or latency. The amount of time elapsed between a user-entered request and the start of a system's response to that request.
- Bandwidth. The volume of data per second that can move between workloads, usually across a network.
- Central processing unit (CPU) interrupts per second. The number of hardware interrupts a process receives per second.
- Average latency. Also called wait time, a measure of the time it takes to receive the first byte after sending a request.
- Average load time. The average time it takes for every request to be delivered.
- Peak response time. The longest time frame it takes to fulfill a request.
- Error rate. Percentage of requests that result in an error compared to all other requests.
- Disk time. Time it takes for a disk to execute a read or write request.
- Session amounts. The maximum number of active sessions that can be open at one time.
These metrics and others help an organization perform multiple types of performance tests.
How to conduct performance testing
Because testers can conduct performance testing with different types of metrics, the process can vary greatly. However, a generic process may look like this:
- Identify the testing environment. This includes test and production environments, as well as testing tools. Understanding the details of the hardware, software and network configurations helps find possible performance issues, as well as aid in creating better tests.
- Identify and define acceptable performance criteria. This should include performance goals and constraints for metrics. For example, defined performance criteria could be response time, throughput and resource allocation.
- Plan the performance test. Test all possible use cases. Build test cases and test scripts around performance metrics.
- Configure and implement test design environment. Arrange resources to prepare the test environment, and then implement the test design.
- Run the test. While testing, developers should also monitor the test.
- Analyze and retest. Look over the resulting test data, and share it with the project team. After any fine-tuning, retest to see if there is an increase or decrease in performance.
Organizations should find testing tools that can best automate their performance testing process. In addition, do not make changes to the testing environments between tests.
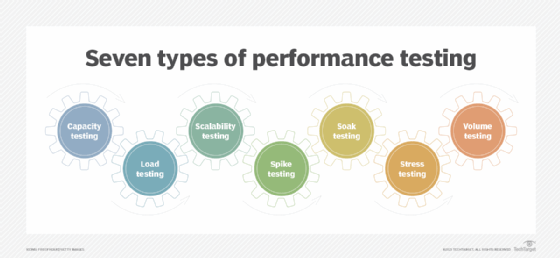
Types of performance testing
There are two main performance testing methods: load testing and stress testing. However, there are numerous other types of testing methods developers can use to determine performance. Some performance test types are the following:
- Load testing helps developers understand the behavior of a system under a specific load value. In the load testing process, an organization simulates the expected number of concurrent users and transactions over a duration of time to verify expected response times and locate bottlenecks. This type of test helps developers determine how many users an application or system can handle before that app or system goes live. Additionally, a developer can load test-specific functionalities of an application, such as a checkout cart on a webpage. A team can include load testing as part of a continuous integration process, in which they immediately test changes to a codebase through the use of automation tools, such as Jenkins.
- Stress testing places a system under higher-than-expected traffic loads so developers can see how well the system works above its expected capacity limits. Stress tests have two subcategories: soak testing and Spike testing. Stress tests enable software teams to understand a workload's scalability. Stress tests put a strain on hardware resources to determine the potential breaking point of an application based on resource usage. Resources could include CPUs, memory and hard disks, as well as solid-state drives. System strain can also lead to slow data exchanges, memory shortages, data corruption and security issues. Stress tests can also show how long KPIs take to return to normal operational levels after an event. Stress tests can occur before or after a system goes live. An example of a stress test is chaos engineering, which is a kind of production-environment stress test with specialized tools. An organization might also perform a stress test before a predictable major event, such as Black Friday on an e-commerce application, approximating the expected load using the same tools as load tests.
-
- Soak testing, also called endurance testing, simulates a steady increase of end users over time to test a system's long-term sustainability. During the test, the test engineer monitors KPIs, such as memory usage, and checks for failures, like memory shortages. Soak tests also analyze throughput and response times after sustained use to show if these metrics are consistent with their status at the beginning of a test.
- Spike testing, another subset of stress testing, assesses the performance of a system under a sudden and significant increase of simulated end users. Spike tests help determine if a system can handle an abrupt, drastic workload increase over a short period of time, repeatedly. Similar to stress tests, an IT team typically performs spike tests before a large event in which a system will likely undergo higher-than-normal traffic volumes.
- Scalability testing measures performance based on the software's ability to scale performance measure attributes up or down. For example, testers could perform a scalability test based on the number of user requests.
- Capacity testing is similar to stress testing in that it tests traffic loads based on the number of users but differs in the amount. Capacity testing looks at whether a software application or environment can handle the amount of traffic it was specifically designed to handle.
- Volume testing, also called flood testing, is conducted to test how a software application performs with a ranging amount of data. Volume tests are done by creating a sample file size, either a small amount of data or a larger volume, and then testing the application's functionality and performance with that file size.
Cloud performance testing
Developers can carry out performance testing in the cloud as well. Cloud performance testing has the benefit of being able to test applications at a larger scale, while also maintaining the cost benefits of being in the cloud.
At first, organizations thought moving performance testing to the cloud would ease the performance testing process, while making it more scalable. The thought process was they could offload the process to the cloud, and that would solve all their problems. However, when organizations began doing this, they started to find that there were still issues in conducting performance testing in the cloud, as the organization won't have in-depth, white box knowledge on the cloud provider's side.
One of the challenges with moving an application from an on-premises environment to the cloud is complacency. Developers and IT staff may assume that the application works the same once it reaches the cloud. They might minimize testing and quality assurance, deciding instead to proceed with a quick rollout. Because the application is being tested on another vendor's hardware, testing may not be as accurate as on-premises testing.
Development and operations teams should check for security gaps; conduct load testing; assess scalability; consider UX; and map servers, ports and paths.
Interapplication communication can be one of the biggest issues in moving an app to the cloud. Cloud environments typically have more security restrictions on internal communications than on-premises environments. An organization should construct a complete map of which servers, ports and communication paths the application uses before moving to the cloud. Conducting performance monitoring may help as well.
Performance testing challenges
Some challenges within performance testing are as follows:
- Some tools may only support web applications.
- Free variants of tools may not work as well as paid variants, and some paid tools may be expensive.
- Tools may have limited compatibility.
- It can be difficult for some tools to test complex applications.
- Organizations should watch out for performance bottlenecks in the following:
- CPU.
- Memory.
- Network utilization.
- Disk usage.
- OS limitations.
- Other common performance problems may include the following:
- Long load times.
- Long response times.
- Insufficient hardware resources.
- Poor scalability.
Performance testing tools
An IT team can use a variety of performance test tools, depending on its needs and preferences. Some examples of performance testing tools are the following:
- Akamai CloudTest is used for performance and functional testing of mobile and web applications. It can simulate millions of concurrent users for load testing as well. Its features include customizable dashboards; stress tests on AWS, Microsoft Azure and other clouds; a visual playback editor; and visual test creation.
- BlazeMeter, acquired by Perforce Software, simulates a number of test cases and operates load and performance testing. It provides support for real-time reporting and works with open source tools, application programming interfaces and more. This testing service includes features such as continuous testing for mobile and mainframe applications and real-time reporting and analytics.
- JMeter, an Apache performance testing tool, can generate load tests on web and application services. JMeter plugins provide flexibility in load testing and cover areas such as graphs, thread groups, timers, functions and logic controllers. JMeter supports an integrated development environment for test recording for browsers or web applications, as well as a command-line mode for load testing Java-based OSes.
- LoadRunner, developed by Micro Focus, tests and measures the performance of applications under load. LoadRunner can simulate thousands of end users, as well as record and analyze load tests. As part of the simulation, the software generates messages between application components and end-user actions, similar to key clicks or mouse movements. LoadRunner also includes versions geared toward cloud use.
- LoadStorm, developed by CustomerCentrix, is a scalable, cloud-based testing tool for web and mobile applications. It works for applications with huge daily traffic and simulates many virtual users to perform real-time load testing. Important features include scalability checks on web and mobile applications and reporting for performance data under load tests.
- NeoLoad, developed by Neotys, provides load and stress tests for web and mobile applications and is specifically designed to test apps before release for DevOps and continuous delivery. An IT team can use the program to monitor web, database and application servers. NeoLoad can simulate millions of users, and it performs tests in-house or via the cloud.
Learn more about three application performance testing objectives.






