web application development
What is web application development?
Web application development is the creation of application programs that reside on remote servers and are delivered to the user's device over the internet. Web apps don't need to be downloaded and instead are accessed through a network. An end user can access a web application through a web browser such as Google Chrome, Safari or Mozilla Firefox. A majority of web applications are written in JavaScript, Cascading Style Sheets (CSS) and HTML5.
Web application development typically has a short development lifecycle led by a small development team. Front-end development for web applications is accomplished through client-side programming. Client refers to a computer application such as a web browser. On the client-side, HTML programming instructs a browser on how to display the on-screen content of webpages, CSS keeps information displayed in the correct format. JavaScript runs JavaScript code on a webpage, making some of the content interactive.
Server-side programming powers the client-side programming and is used to create the scripts that web applications use. Scripts are written in multiple scripting languages such as Ruby, Java and Python. Server-side scripting creates a custom interface for the end user and hides the source code that makes up the interface.
Databases such as MySQL and MongoDB are used to store data in web application development.
Web application development skills
Web application development requires various skills, even ones that aren't exclusively technical. For example, while coding skills are essential, developers must also understand what makes a good user interface (UI) and how search engine optimization (SEO) works. Skills required for web application development professionals includes the following:

- UI and user experience (UX) design principles. User-friendly design is key, particularly for nontechnical users, so having a good grasp of UI and UX is crucial for web app developers. Apps often must be optimized for both desktop and mobile devices. Mobile app UIs for smartphones have different requirements than desktop UIs.
- Programming languages. Common programming languages that web app developers need a firm grasp of include HTML, CSS, JavaScript and Python.
- Analytical skills. Analytical skills, especially for data on market trends and consumer product purchases, could benefit web app creators. Developers can tailor the design of their apps to appeal to specific audiences who are engaged or interested in certain products or vertical markets if needed.
- SEO principles. People often use search engines to discover web apps. Given that, developers must know what to include to make their apps match or surpass competitor offerings and rank high in search engine results.
- Version control. Different versions of the app might have bugs or other issues, so tracking changes helps identify and mitigate problems in each version without starting over. Project management tools such as Atlassian's Jira help with version control.
- Communication. This is an example of a high-level soft skill that benefits tech professionals such as web app developers. Communicating directly with consumers or clients to build a web application that meets their needs is key.
- Testing. Web-based applications often have large amounts of information that contains mistakes, so the testing and debugging processes for web applications tend to be more in-depth than other forms of software. Software development tests for web applications include security, performance, load, stress, accessibility, usability and quality assurance. Other tests that can be performed for web applications include HTML/CSS validation or cross-browser tests. Many of these tests can be automated.
Web application development frameworks
Web app developers don't need to start from scratch every time. There are a variety of back-end and front-end frameworks available with pre-built modules and components. Popular frameworks include the following:
- Angular. Angular is one of the foremost JavaScript frameworks. Google developed it, and it's used by companies such as Netflix and PayPal.
- ASP.NET. Microsoft created this framework to enable web developers to use various .NET programming languages, such as C#. It can build web applications that are cross-platform and run on the Apple macOS, Linux and Microsoft Windows operating systems.
- Django. This Python framework was released in 2005 and offers a comprehensive list of functionalities. It's ideal for large-scale development projects.
- Laravel. Laravel is built with the Hypertext Preprocessor (PHP) programming language and can be used to build various types of web applications. It features access controls for security purposes.
- React.js. Although considered a framework, React.js is technically a JavaScript-based library so developers can assemble the components needed for compelling UIs in apps.
- Ruby on Rails. This framework is based on the Ruby on Rails programming language and includes libraries and tools for developers to streamline their processes.
- Svelte. This framework is open source and JavaScript-based, allowing developers to build interactive apps with simplicity due to functionalities such as automatic updating.
- Vue.js. This JavaScript framework was developed by a team of independent developers who wanted to give other developers an easy-to-learn web development framework.
6 steps in web application development
A variety of tools and frameworks exist to help developers start building a web app, so there's no single approach. However, the steps involved in the web application development process are similar in each web app development scenario. The general workflow entails the following six steps:
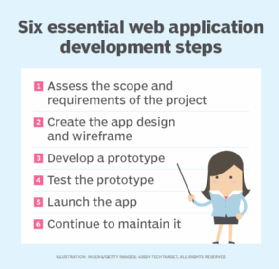
- Assessing scope and requirements. This step entails defining what end users will do with the finished app and which features and functionalities are needed for the app to achieve its intended purposes.
- App design and wireframing. Developers create skeletons or wireframes that map out what the app will look like on a screen.
- Developing a prototype. A prototype is built as a means of testing all facets and functionalities of the app to ensure they work as intended.
- Testing. The development team uses a runtime environment to rigorously test the prototype and ensure kinks or bugs are ironed out before launch.
- Launching. Once the prototype is tested and proven successful, the app can be launched for real-world use.
- Continuous maintenance. If needs or features change or if the app's functionality stops working properly, continuous monitoring and maintenance is needed to address these issues.
Web application development tools
Many tools are available to simplify and expedite the web app development process. Many of these are free, open source tools. A sampling of them includes the following:
- Bootstrap. This open source, front-end development tool provides a range of premade UI components so developers don't have to do much customization with HTML and CSS.
- Docker. This is a popular containerization platform, where web applications can be placed inside portable runtime environments that can be deployed in different locations and on various servers. This is useful for collaboration with other developers.
- GitHub. This popular version control platform serves as a code repository so developers can retrieve modules and components as needed for web app development.
- JQuery. This open source JavaScript library simplifies HTML-based tasks and automates many coding tasks.
- Node.js. This back-end tool is a JavaScript runtime environment. With Node.js, developers can see if their code works properly.
- Sublime Text. This code and text editor facilitates web app development with a tool set that organizes components for modification.
- Visual Studio Code. This code editor lets developers modify and debug their code as needed. It supports programming languages typically used in web app development.
Native apps vs. hybrid apps
Web applications are sometimes contrasted with native apps and hybrid apps. Native apps are applications that are developed specifically for a particular platform or device and installed on that device. Native apps can use device-specific hardware, such as GPS or cameras and typically have an advantage in functionality over web or hybrid apps.
Hybrid apps are a combination of native and web apps. The inner workings of a hybrid application are similar to a web application, but it's installed like a native app. Hybrid applications have access to internal application programming interfaces that can access device-specific resources similar to a native application.
Native apps are faster and perform more efficiently because they're designed to be platform-specific. Hybrid apps have the same navigational elements as web apps. There's also no offline mode for hybrid applications.
How to become a web application developer
Aspiring web app developers must obtain pertinent degrees or certifications. Web design and computer science degrees both can help developers get started with a web app developer career. Examples of professional certifications in this area include Meta's Front-End Developer, Back-End Developer and Introduction to Front-End Development, Google's UX Design and IBM's Introduction to Web Development with HTML, CSS, JavaScript.
Prepping for a web development career also requires candidates to acquire the hard and soft skills needed to succeed in the role. The hard skills include programming languages such as HTML5, CSS, JavaScript, Python and PHP. They can be acquired with a software engineering or related degree, giving graduates multiple career paths including web development. A soft skill such as project management will allow web app developers to efficiently manage their time and resources.
Web 3.0 marks a new age in web app development, requiring new skills and approaches. Learn more about Web 3.0 and what is required.





