Prevent AI bias in predictive applications before it starts
While AI offers predictive insights, developers must train AI models to ensure accurate results. These five types of input, in particular, can cause poor output from the finished app.

The proliferation of artificial intelligence APIs, tools and frameworks has made it easier than ever for software developers to add AI capabilities into applications. But, while these apps can achieve astonishing results, developers must train AI models carefully with a thorough vetting process.
The math behind AI models is quantifiable and easy to read, but AI bias from human-controlled input can lead to incomplete, wrong, noncompliant or even maliciously false results. Organizations should be mindful of these potential issues to identify them quickly.
Don't take shortcuts with AI governance
Behind every estimation an AI model returns lies an amount of guesswork that gets abstracted away from users. Developers must determine whether the math behind an AI model and that model's training are sufficiently reliable before users experience the application. Humans increasingly rely on AI-driven quantitative data analysis in applications; the onus is on the AI developer to ensure it's accurate.
Numerous research groups work on making AI decisions semitransparent and a model's math more reviewable, but these methods are experimental and costly. Enterprises must follow practical ways to ensure they aren't seeing a false reality because of bias in AI models.
AI-driven optimization and automation can improve business processes when implemented correctly. As organizations build AI models, modern full-stack developers will serve as the data scientists for these types of projects. The rapid spread of AI makes it critical to put architectural and procedural safeguards in place to ensure the quality of AI artifacts. As one prominent example of AI gone wrong, in 2016, Microsoft launched an AI-driven chatbot named Tay that it quickly shut down after end-user input turned it into a racist, misogynist and vulgar entity. However, most inaccurate AI predictions are accidental as opposed to malicious; they occur due to a lack of subject matter knowledge or AI experience or a failing in the model training process.
Assess these points in the AI development process where input influences the algorithms' results -- for better or worse.
Training input
During AI training, an algorithm consumes pre-annotated validation sets, dictionaries and commercial content packs to pull into a predictive model. The AI model inherits its ability to parse input from the training content provided by one or more humans. Then, the model churns that input into predictions.
For example, to teach an AI model how to recognize numbers on a photo, the developer typically creates a validation set with hundreds of images that contain numbers. Before uploading, they manually provide the AI application with these numbers so that the algorithms can fit a model that automatically recognizes numbers on photos.
Training AI systems is no trivial task. In an experiment, I attempted to see if the Amazon Rekognition image recognition service could pick up numbers on a seven-segment display. It could not reliably identify these numbers, despite its out-of-the-box functionality. In this case, the provided samples might not have included seven-segment numbers.
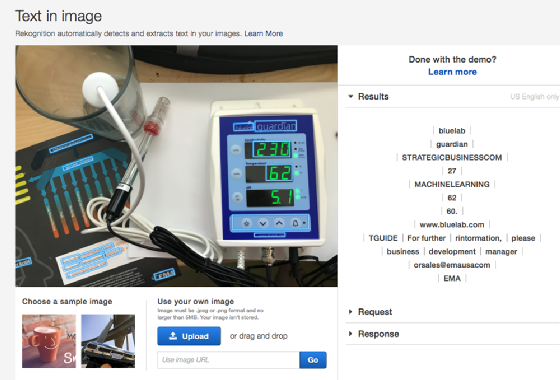
The Rekognition example shows an innocent training oversight that created a gap in the AI model. Other oversights -- intentional or not -- can result from human bias and lead to suboptimal results or even legal liabilities. This issue becomes even more insidious when an AI model delves into areas where the reliability of the predictions is difficult to verify.
Imagine that you train an AI model to find the optimal location for a bar or retail location, but neglect to include the market information that you can derive from reviews on Yelp, Facebook and Google. This unstructured external data is freely available via API and contains important information on the quality of potential competition, and preferences of the local population. If you leave out this data, your AI model might still be well-fitted to the training data, but it will be blind to opportunities hidden in user reviews on those sites and other traditional demographic data sources.
Commercial data sets
In addition to manual annotation, enterprises can obtain turnkey content packs, API content and dictionaries that teach the AI model about some defined aspect of the world. For example, I can use an IBM content pack that contains menus for 120,000 restaurants to teach an AI model about the food and drink of a certain cuisine.
These turnkey content packs can save a significant amount of time and money training an AI model, but the team must review the content for bias and completeness. In the above example, if the restaurant database lacked a specific type of German restaurant, developers and end users should know about the omission to ensure the pack still fits the purpose of the training.
Dictionaries
Dictionaries provide concept definitions and synonyms to train an AI model in a specific topic area. IBM Watson, Amazon SageMaker and Azure Machine Learning Studio each contain a general broad dictionary to parse language. Additionally, developers can plug in commercially available dictionaries to teach the AI model terms specific to the target industry, such as engineering, mathematics or medicine. If there are still gaps in the model, they can define a custom dictionary.
Dictionaries have a large effect on the AI model's ability to recognize relevant input variables, so carefully review all dictionaries for accidental or intentional bias. A bad dictionary, for example, might cause female applicants to slip below male applicants in consideration for a job opening, due to the dictionary not including the complete range of expected job titles for women vs. men.
Transfer learning
Organizations can use an already trained AI model for a new purpose, a technique referred to as transfer learning. Developers typically create their own instance of this AI model and then perform any necessary additional training and parameter changes. But just because a model is well-suited for one task doesn't mean it can seamlessly take on a different one.
For example, let's assume that a developer downloads an instance of an AI model that provides great results when asked to summarize computer science publications into a short daily digest. The developer's goal is to train this model to also summarize legal magazines, so he or she adds a legal dictionary. While this approach makes sense, the developer cannot be sure of the objective character of the original model. To assess potential AI bias, developers must request access to these materials or evaluate the model's output to a large number of example queries, which can be a time-consuming process.
The feedback loop
Developers should aim to create an optimal feedback loop, which enables an AI model to continuously learn from data sets and tasks. But it's important to protect the model against two types of AI bias that can come from the loop: feedback and external input.
With feedback bias, an AI model fails to properly assess the ramifications of its results. For example, consider an AI model that learns from a VMware administrator to provision storage pools. The AI system could use average storage latency in milliseconds, combined with storage downtime per week, as the critical metrics to validate a best-practice approach to storage pool creation. However, there are many potential long-term consequences to this provisioning method -- reliability problems and cost overruns in the real world -- that the model won't consider when it assesses those two metrics. It is often difficult to establish the best possible feedback loops for reinforcement learning, as many dependencies are simply unknown, even to subject matter experts.
In the case of the Microsoft chatbot, end users manipulated the model just by interacting with the bot. Malicious attacks can exploit the biggest strengths of deep learning: the ability to adjust a predictive model to situational and external feedback. Theoretically, these attacks might come from a competing company or simply via organic and implicit bias, in which certain user groups act against the interest of the organization. On the other end of the spectrum, Apple's Siri and Amazon's Alexa both lack the ability to adjust instantly to user input. Instead, they rely on a manually reviewed and tested pipeline before their behavior is modified.
While there is no automated remedy for AI bias, procedural safeguards for training AI, in combination with a responsible and critical attitude on the part of development teams, can help on the journey toward the safe, productive use of the technology.







